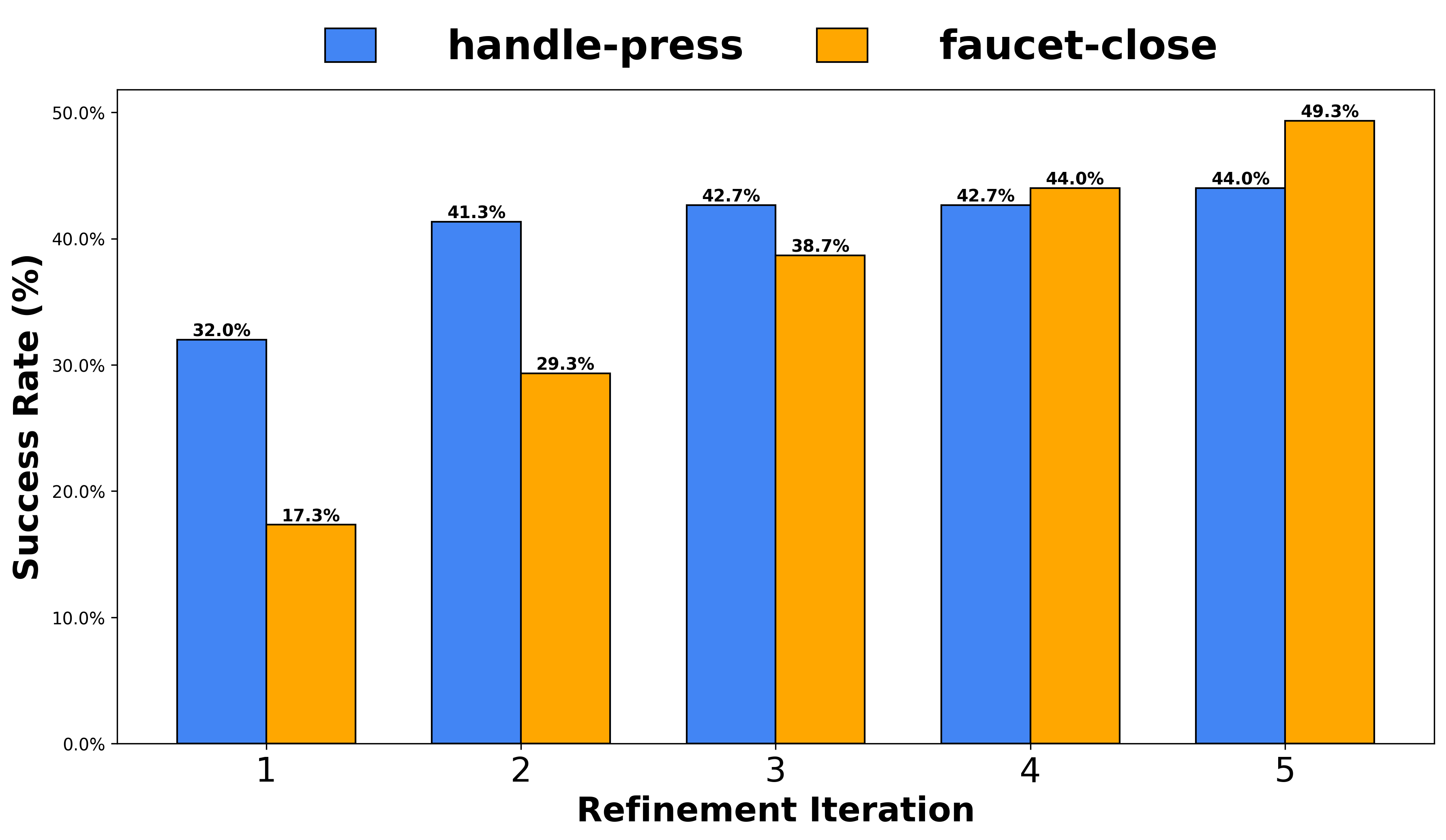
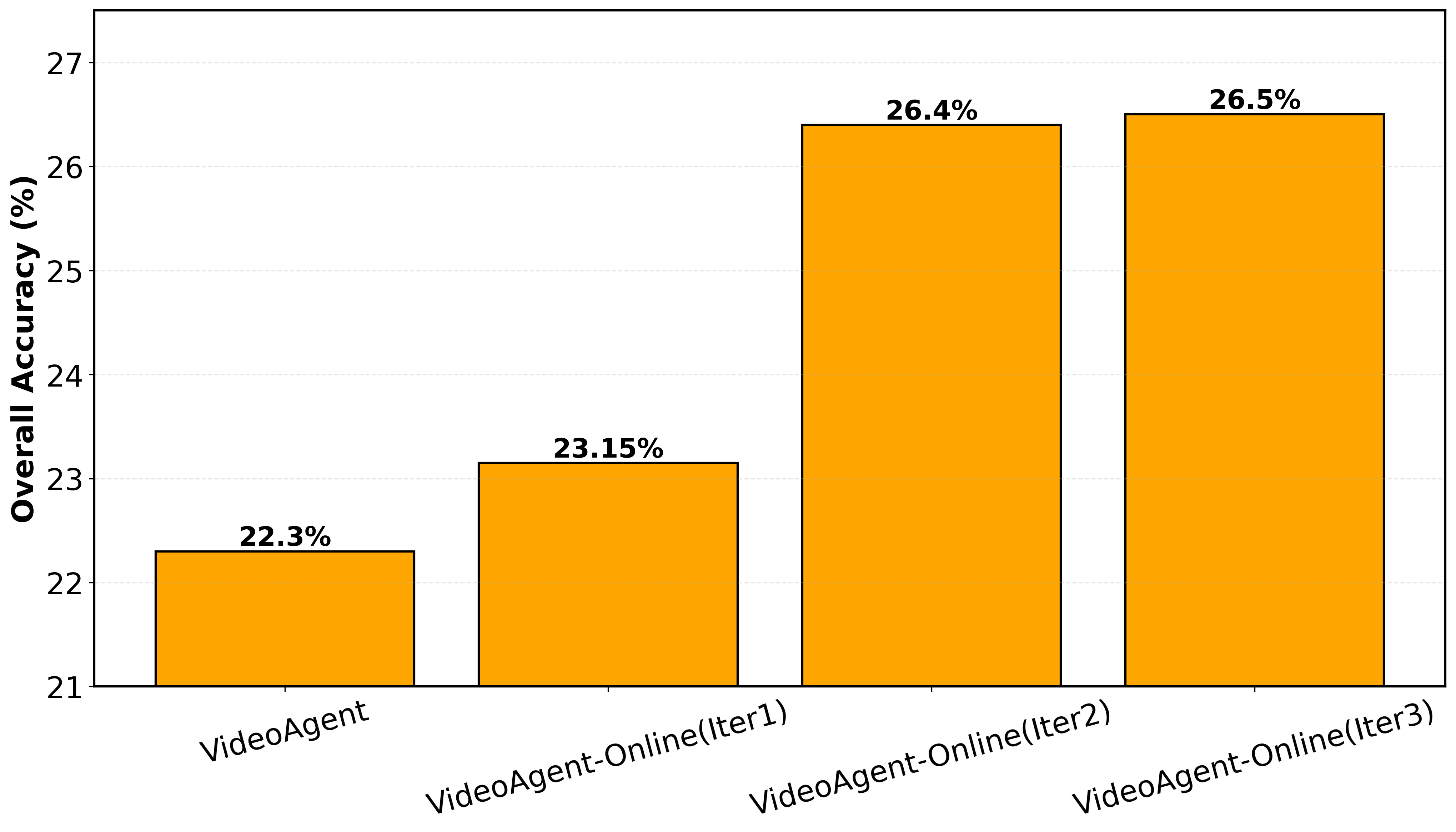
Meta-World Results. The mean success rates of baselines and VideoAgent on 11 simulated robot manipulation environments from Meta-World. VideoAgent consistently outperforms baselines across all tasks.
| Task | AVDC | AVDC-Replan | VideoAgent | VideoAgent-Online (Iter1) | VideoAgent-Online (Iter2) | VideoAgent-Online-Replan |
|---|---|---|---|---|---|---|
| Door Open | 30.7% | 72.0% | 40.0% | 41.3% | 44.0% | 80.0% |
| Door Close | 28.0% | 89.3% | 29.3% | 32.0% | 29.3% | 97.3% |
| Basketball | 21.3% | 37.3% | 13.3% | 17.3% | 18.7% | 40.0% |
| Shelf Place | 8.0% | 18.7% | 9.3% | 12.0% | 18.7% | 22.7% |
| Button Press | 34.7% | 60.0% | 38.7% | 45.3% | 46.7% | 72.0% |
| Button Press Topdown | 17.3% | 24.0% | 18.7% | 14.7% | 16.0% | 40.0% |
| Faucet Close | 12.0% | 53.3% | 46.7% | 38.7% | 49.3% | 58.7% |
| Faucet Open | 17.3% | 24.0% | 12.0% | 13.3% | 21.3% | 36.0% |
| Handle Press | 41.3% | 81.3% | 36.0% | 36.0% | 44.0% | 85.3% |
| Hammer | 0.0% | 8.0% | 0.0% | 0.0% | 1.3% | 8.0% |
| Assembly | 5.3% | 6.7% | 1.3% | 4.0% | 1.3% | 10.7% |
| Overall | 19.6% | 43.1% | 22.3% | 23.2% | 26.4% | 50.0% |












































.png)